ジェルばんは! KMC-id: prime, id:PrimeNumber のそすうぽよだよ〜。
みなさん、Pietプログラミングを楽しんでいますか?
知らない人のために解説すると、Pietはドット絵がソースコードのプログラミング言語で、いわゆる「難解プログラミング言語」の一つです。
以下のような「ドット絵」がソースコードになっています!
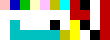
Pietの仕様
Pietについてより詳しく知りたい人は以下のスライドを読むのがおすすめです。
www.slideshare.netPietの本家サイト(英語): DM's Esoteric Programming Languages - Piet
Pietの仕様について、この記事を読むのに必要な部分だけ説明します。
Pietの画像は、内部的に17種の命令から構成された命令列として解釈されます。 Pietでは、実行時にただ一つのスタックを持ち、17種の命令はスタックを操作しつつ入出力や条件分岐を行います*1。
Pietのスタック操作
17種の命令はスタックに対する操作の違いにより、以下の通りに分類することができます。
- スタックに値を1つ積む: push, in(char), in(number)
- スタックから値を1つ取り除く: pop, switch, pointer, out(char), out(number)
- スタックから値を1つ取り除き、それに応じて新たな値を1つ積む: not
- スタックから値を2つ取り除き、それに応じて新たな値を1つ積む: add, subtract, multiply, divide, mod, greater
- スタックから値を1つ取り除き、それに応じて新たな値を2つ積む: duplicate
- 特殊な操作(後述): roll
rollは特殊な操作で、
- まず、スタックから2回pop操作を行う。このときの値を1回めから順にcount, depthとする。
- countが非負のときは、count回以下の操作を繰り返す(以後これをroll-stepと呼ぶことにします)
- スタックの1番上の要素を、depth番目まで移動する(その分、2番目からdepth番目までの要素は1個分スタックのトップに近づく)
- countが負の場合は、逆操作(depth番目の要素を1番上に持ってくる)をabs(count)回繰り返す。
例えば、スタックのサイズが9で、depth=8, count=3のときは次のような操作になります。
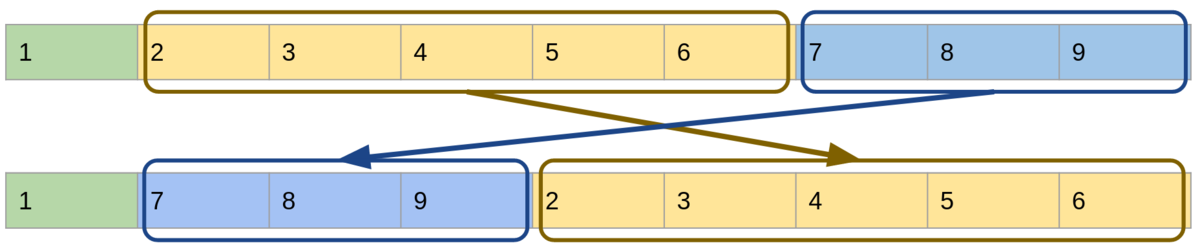
Pietにはヒープメモリに相当する概念はありませんが、このroll操作によって自由にスタックを操ることで、チューリング完全な計算能力を得ることができます。
rollの実装
さて、このroll操作を普通の配列上に実装したスタックで実装するとどうなるでしょうか?
当然、配列上のdepth個の要素すべてを移動しなければならないため、少なくともdepthに比例した計算量が必要です。実のところ、rollは配列上で で実現可能です。
簡潔な実装として、列のreverseを3回行って実現する方法があります。先ほどと同じ、depth=8, count=3のときは次のようにして実現できます。
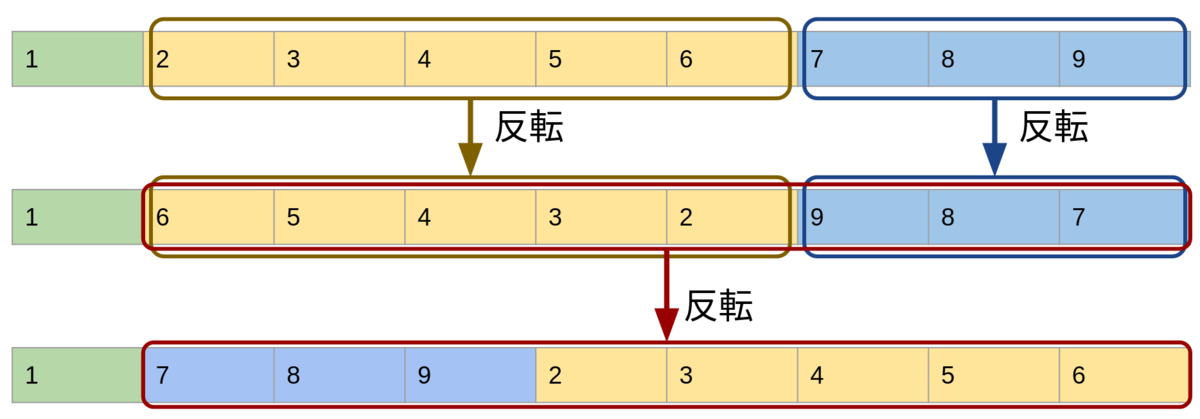
実用上高速な方法はRustの標準ライブラリ実装のコメントを読むとわかりやすいです。 rust/rotate.rs at e1b71feb592ba64805689e2b15b9fa570182c442 · rust-lang/rust · GitHub
rollにふさわしいデータ構造とは
さて、スタックを保持するデータ構造を工夫することで、もっと高速にrollを行う方法はないでしょうか?
一つの方法として、平衡二分木を使う方法があります。平衡二分木を順序を持った列を管理するデータ構造だと思うと、以下の操作を行うことができます(はスタックのサイズ)。
- insert: 新たな要素を任意の場所に挿入する
- erase: 列の任意の位置の要素を削除する
- split: 列を任意の位置で2つに分割する
- concatenate: 2つの列を連結する
- build: 配列から対応する平衡二分木を構築する
- dump: 平衡二分木から対応する配列を構築する
スタックに対するpush, popはそれぞれinsert, eraseで実現できます。rollはsplit, concatenateを用いて次のように書くことができます(Rust風疑似コード、とする)
fn roll(tree: Tree, depth: usize, count: usize) { let (left, remain) = tree.split(depth); let (middle, right) = remain.split(count); left.concatenate(right.concatenate(middle)) }
したがって、平衡二分木を用いるとすべての命令をで処理することができます。めでたしめでたし。
ではなく、配列で実装したときと比べて、roll以外の操作がから
に悪化してしまっています。roll以外の命令を頻繁に実行する場合(実際、多くの場合はそうなります)、これはあまり嬉しくありません。
高速なPietの処理系には、さらに効率的なデータ構造が必要です。
これが一番速いと思います
今回紹介するデータ構造は id:joisino (KMC-ID: joisino) さんの考案したものです。この記事はjoisinoさんの許諾を得て執筆しています。
性能
- roll以外: 償却
- roll: (償却ではなく、厳密に)
roll以外が償却定数時間になっているのが大きなポイントです。また、実用上も高速な実装が可能です。
データ構造
スタックのtopからt個()を(配列等で実装した)通常のスタックで、残りをsplit/concatenateのできる平衡二分木で管理します。
操作
roll
- スタックから全部取り出して要素数 t の平衡二分木を作る
- 本体の平衡二分木と concatenate する
- roll する
- 平衡二分木の最後の
要素を split する
- split した要素をスタックに詰める
push
- 通常のスタックに push する
- 通常のスタックの要素が
に達した時 ★
- スタックの最初の
- 本体の平衡二分木と merge する
- スタックの最初の
pop
- 通常のスタックから pop する
- ただし、スタックが空の場合、以下の操作を行ってから pop する ★
- 平衡二分木の最後の
- split した要素をスタックに詰める
- 平衡二分木の最後の
push, pop 操作で ★ が起こるのは最悪でも 回 push, pop 操作を連続して行うごとなので、これで償却
になります
さらなる最適化
roll操作において、depthが通常のスタックに収まるほど小さい場合は、配列に対するroll操作のみで完結させることができ実用上高速です。
headに収まるという条件から、であることにも変わりはありません。
実装
あらかじめ実装したものがこちらになります
平衡二分木の実装は赤黒木です。頻繁に木に対する変更を行うこと、rollを厳密(償却ではなく)に保つためには平衡二分木の操作が厳密
である必要があることから選択しました。
赤黒木の実装はlibrary/red-black-tree.cpp at master · ei1333/library · GitHubをもとに、いくらかの変更を施して利用しています。
ベンチマーク
漸近的計算量の改善だけでなく、実際にも速くなるか確かめたいところです。
- スタックに対するpush, pop, rollクエリを6 : 3 : 1の比率でランダムに選択し実行
- Pietにおけるroll命令を一回実行するたびに、スタック対して2回popが呼ばれること、popするにはpushする必要があること、pushの方が多くないとスタックが成長しないこと、等を考慮しこの比率に設定
- rollのdepthは、depthの対数が一様分布になるようにランダムに選択
- これは、参照の局所性のあるプログラムの動作を模倣したもの
- rollのcountは32bit整数の範囲から一様ランダムに選択
- 内部でdepthでmodを取ることから、おおよそ0以上depth未満の一様ランダム
比較対象には、配列(のみ)による実装と赤黒木(のみ)による実装を用意しました。
- CPU: Ryzen 9 5950X
- OS: Ubuntu 20.04.4 LTS (Linux 4.19.128-microsoft-standard) on WSL2 on Windows 10 Home 21H1
- コンパイラ: GCC (Ubuntu 9.4.0-1ubuntu1~20.04.1)
- コンパイラオプション:
-std=c++17 -O2 -march=native -mtune=native -Wall -Wextra
結果
クエリ数Qを10万、30万、100万、300万、1000万と変えて実行時間を計測しました。
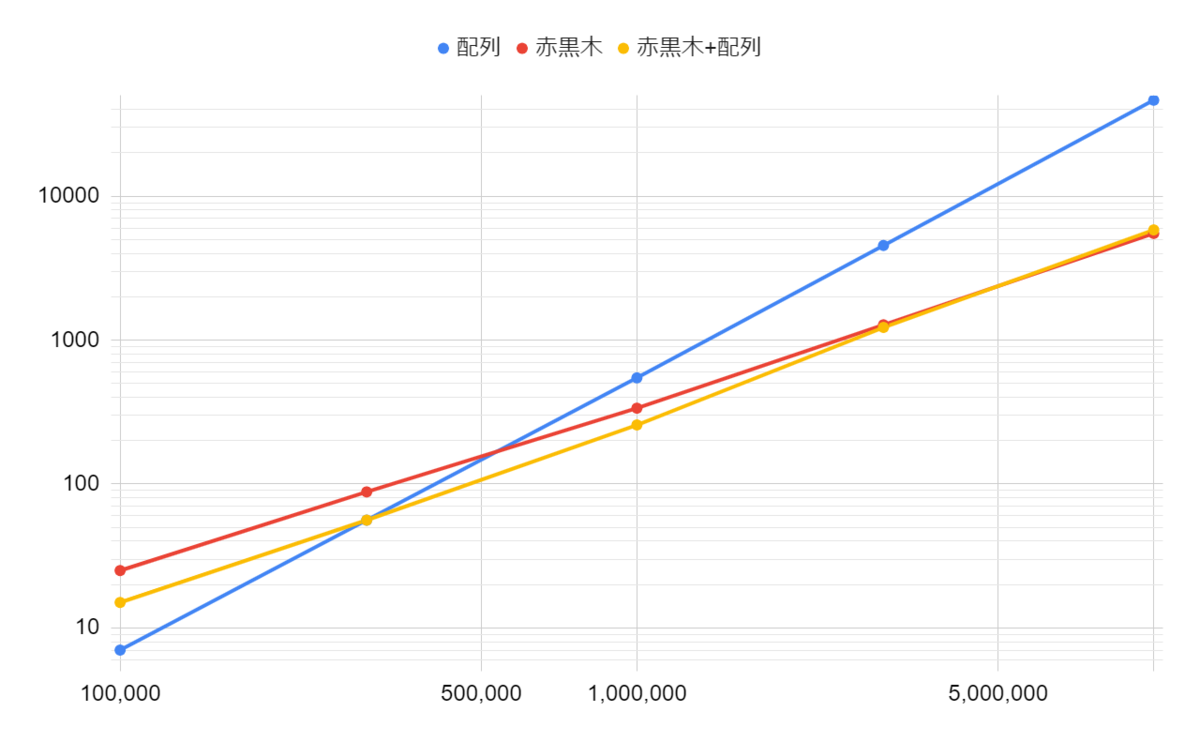
考察
Q=1,000,000では他の実装よりも高速になりました! しかし、Q=100,000では配列実装より遅く、Q=10,000,000では赤黒木実装より遅くなってしまいました。なぜでしょうか?
一般に、平衡二分木は間接参照を多用するため、現代のコンピュータではかなりオーバーヘッドが大きいことが知られています。 一方、配列実装ではメモリに対してシーケンシャルにアクセスするパターンが多いため、性能を出しやすいです。 そのため、漸近的計算量が悪くても、スタックの大きさが小さいうちは配列実装の方が高速になります。 スタックの大きさに応じて赤黒木を併用するかどうかを切り替えると、実用上良いかもしれません*2。
また、そもそも今回導入したデータ構造では全クエリを通しての漸近的計算量を改善するものではないため、赤黒木だけの実装と比べると定数倍勝負になってしまいます。 赤黒木のみの実装と比較すると、push/popの計算コストをrollに押し付けることでpush/popの償却計算量を改善しているため、rollの計算量は定数倍悪化しています。 赤黒木のみとどちらが速いかは、クエリ中のrollの比率によって変わってきます。 実際、rollの比率をベンチマークに用いた1/10から1/20にすると、Q=10,000,000でも赤黒木+配列のハイブリッドの方が赤黒木のみの実装より3割程度高速になりました。
今後の課題
赤黒木の代わりにB+木等を使うと、間接参照のオーバーヘッドを緩和できる可能性があるので、暇があれば試してみたいです(あるいは誰か実装してくれ頼む!)。 あるいは別のデータ構造(フィンガーツリーの亜種とか…?)で、よりよい性能を示すものがあるかもしれないので、それについても調べて(できれば実装もして)みたいです。
ではみなさん、よいPietライフを~!